
| C-DVM - оглавление | Часть 1 (1-4) | Часть 2 (5-11) | Часть 3 (Приложения) |
| создан: апрель 2001 | - последнее обновление 06.10.02 - |
5.1.1 Определение параллельного цикла
Моделью выполнения C-DVM программы, как и программ на других языках с параллелизмом по данным, является модель SPMD (одна программа - множество потоков данных). На все процессоры загружается одна и та же программа, но каждый процессор в соответствии с правилом собственных вычислений выполняет только те операторы присваивания, которые изменяют значения переменных, размещенных на данном процессоре (собственных переменных).
Таким образом, вычисления распределяются в соответствии с размещением данных (параллелизм по данным). В случае размноженной переменной оператор присваивания выполняется на всех процессорах, а в случае распределенного массива - только на процессоре (или процессорах), где размещен соответствующий элемент массива.
Определение " своих" и пропуск " чужих" операторов может вызвать значительные накладные расходы при выполнении программы. Поэтому спецификация распределения вычислений разрешается только для циклов, которые удовлетворяют следующим условиям:
Цикл, удовлетворяющий этим условиям, будем называть параллельным циклом. Управляющая переменная последовательного цикла, охватывающего параллельный цикл или вложенного в него, может индексировать только локальные (размноженные) измерения распределенных массивов.
5.1.2 Распределение витков цикла. Директива PARALLEL
Параллельный цикл специфицируется следующей директивой:
| parallel-directive | ::= | PARALLEL loop-variable... ON iteration-align-spec [ ; reduction-clause] [ remote-access-clause ] ; shadow-renew-clause] [ ; [ ; across-clause ] |
| iteration-align-spec | ::= | align-target iteration-align-subscript... |
| iteration-align-subscript | ::= | [ int-expr ] |
| | | [ do-variable-use ] | |
| | | [] | |
| loop-variable | ::= | [ do-variable ] |
| do-variable-use | ::= | [ primary-expr * ] do-variable [ add-op primary-expr ] |
Замечание. Заголовки в гнезде циклов должны быть записаны с помощью макросов DO(var,first,last,step) или FOR(var,times) (сокращение для DO(var,0,times-1,1)).
Директива PARALLEL размещается перед заголовком цикла и распределяет витки циклов в соответствии с распределением массива или шаблона. Семантика директивы аналогична семантике директивы ALIGN, где индексное пространство выравниваемого массива заменяется индексным пространством цикла. Индексы циклов в списке loop-variable... перечисляются в том порядке, в котором размещены соответствующие операторы DO в тесно-гнездовом цикле.
Синтаксис и семантика отдельных частей директивы описаны в следующих разделах:
| reduction-clause shadow-renew-clause remote-access-clause across-clause |
- раздел 5.1.4, - раздел 6.2.2, - раздел 6.3.1, - раздел 6.2.3. |
Пример 5.1. Распределение витков цикла с регулярными вычислениями.
DVM(DISTRIBUTE B[BLOCK][BLOCK]) float B[N][M+1];
DVM(ALIGN [i][j] WITH B[i][j+1]) float A[N][M], C[N][M], D[N][M];
. . .
DVM(PARALLEL [i][j] ON B[i][j+1])
DO(i, 0, N-1, 1)
DO(j, 0, M-2, 1)
{
A[i][j] = D[i][j] + C[i][j];
B[i][j+1] = D[i][j] – C[i][j];
}
Цикл удовлетворяет всем условиям параллельного цикла. В частности, левые части операторов присваивания одного витка цикла A[I][J] и B[I][J+1] размещаются на одном процессоре благодаря выравниванию массивов А и В.
Если левые части операторов присваивания размещены на разных процессорах (распределенный виток цикла), то цикл необходимо разделить на несколько циклов.
В следующем примере переменная описана в теле цикла. Это, так называемая, приватная переменная витка цикла, т.е. ее значение безразлично в начале витка и не используется по окончании витка. Использовать в цикле подобным образом переменные, описанные вне цикла, запрещается из-за двух потенциальных проблем для параллельного выполнения витков цикла: зависимость по данным между витками и неконсистентное состояние переменной при выходе из цикла.
Пример 5.3. Объявление приватной переменной.
DVM(PARALLEL [i]]j] ON A[i][j] )
FOR(i, N)
FOR(j, N)
{float x; /* variable private for every iteration */
x = B[i][j] + C[i][j];
A[i][j] = x;
}
5.1.4 Редукционные операции и переменные. Спецификация REDUCTION
Очень часто в программе встречаются циклы, в которых выполняются редукционные операции - в некоторой переменной суммируются элементы массива или вычисляется максимальное (минимальное) значение. Витки таких циклов можно распределять, если указать спецификацию REDUCTION.
| reduction-clause | ::= | REDUCTION reduction-op... |
| reduction-op | ::= | reduction-op-name ( reduction-variable ) |
| | | reduction-loc-name ( reduction-variable , loc-variable) | |
| reduction-variable | ::= | array-name |
| | | scalar-variable-name | |
| reduction-op-name | ::= | SUM |
| | | PRODUCT | |
| | | MAX | |
| | | MIN | |
| | | AND | |
| | | OR | |
| reduction-loc-name | ::= | MAXLOC |
| | | MINLOC |
Редукционными переменными не могут быть распределенные массивы. Редукционные переменные вычисляются и используются только в операторах определенного вида - редукционных операторах.
Второй параметр функций MAXLOC и MINLOC -- это переменная, описывающая элемент с найденным максимальным (соответственно, минимальным) значением. Обычно это индекс элемента в одномерном массиве или структура, содержащая индексы в многомерном массиве.
Пример 5.4. Спецификация редукции.
S = 0;
X = A[0];
Y = A[0];
MINi = 0;
DVM(PARALLEL [i] ON A[i];
REDUCTION SUM(S) MAX(X) MINLOC(Y,MIMi))
FOR(i, N)
{
S = S + A[i];
X = max(X, A[i]);
if(A[i] < Y) {
Y = A[i];
MINi = i;
}
}
5.2 Вычисления вне параллельного цикла
Вычисления вне параллельного цикла выполняются по правилу собственных вычислений. Оператор присваивания lh = rh; может быть выполнен на некотором процессоре, только если lh присутствует на нем. Если lh – элемент распределенного массива (и присутствует не на всех процессорах), то такой оператор (оператор собственных вычислений) будет выполняться только на том процессоре (или на тех процессорах), где присутствует данный элемент распределенного массива. Все данные, используемые в выражениях rh, должны также присутствовать на этом процессоре. Если какие-либо данные из выражений и rh отсутствуют на нем, то их необходимо указать в директиве удаленного доступа (см. 6.1.2) перед этим оператором.
Если lh является ссылкой на распределенный массив А и существует зависимость по данным между rh и lh, то распределенный массив необходимо размножить с помощью директивы REDISTRIBUTE А[]…[] или REALIGN А[]…[].
Пример 5.5. Собственные вычисления.
#define N 100 DVM(DISTRIBUTE [BLOCK][]) float A[N][N+1]; DVM(ALIGN [I] WITH A[I][N+1]) float X[N]; . . . /* reverse substitution of Gauss algorithm */ /* own computations outside the loops */ X[N-1] = A[N-1][N] / A[N-1][N] DO(J, N-2,0, -1) DVM(PARALLEL [I] ON A [I][]; REMOTE_ACCESS X[j+1]) DO(I, 0, J, 1) A[I][N] = A[I][N] – A[I][J+1] * X[J+1]; /* own computations in sequential loop, */ /* nesting the distributed loop */ X[J] = A[J][N] / A[J][J] }
Отметим, что A[J][N+1] и A[J][J] локализованы на том процессоре, где размещается X[J].
6 Cпецификация удаленных данных
6.1 Определение удаленных ссылок
Удаленными данными будем называть данные, используемые на данном процессоре, но размещенные на другом процессоре. Ссылки на такие данные будем называть удаленными ссылками. Рассмотрим обобщенный оператор
if (…A[inda]…) B[indb] = …C[indc]…
где
A, B, C - распределенные
массивы,
inda, indb, indc - индексные
выражения.
В модели DVM этот оператор будет выполняться на процессоре, на котором размещен элемент B(indb). Ссылки A(inda) и C(indc) не являются удаленными ссылками, если соответствующие им элементы массивов A и C размещены на процессоре том же процессоре. Единственной гарантией этого является выравнивание A(inda), B(indb) и C(indc) в одну точку шаблона выравнивания. Если выравнивание невозможно или не было выполнено, то ссылки A(inda) и/или C(indc) необходимо специфицировать как удаленные ссылки. В случае многомерных массивов данное правило применяется к каждому распределенному измерению.
По степени эффективности обработки удаленные ссылки разделены на два типа: SHADOW и REMOTE.
Если массивы B и C выровнены и
inda = indc ± d ( d – положительная целочисленная константа),
то удаленная ссылка C(indc) принадлежит типу SHADOW. Удаленная ссылка на многомерный массив принадлежит типу SHADOW, если распределяемые измерения удовлетворяют определению типа SHADOW.
Удаленные ссылки, не принадлежащие типу SHADOW, составляют множество ссылок типа REMOTE.
Особым множеством удаленных ссылок являются ссылки на редукционные переменные (см. 5.2.4), которые принадлежат типу REDUCTION. Эти ссылки могут использоваться только в параллельном цикле.
Для всех типов удаленных ссылок возможны два вида спецификаций: синхронная и асинхронная.
Синхронная спецификация задает групповую обработку всех удаленных ссылок для данного оператора или цикла. На время этой обработки, требующей межпроцессорных обменов, выполнение данного оператора или цикла приостанавливается.
Асинхронная спецификация позволяет совместить вычисления с межпроцессорными обменами. Она объединяет удаленные ссылки нескольких операторов и циклов. Для запуска операции обработки ссылок и ожидания ее завершения служат специальные директивы. Между этими директивами могут выполняться другие вычисления, в которых отсутствуют ссылки на специфицированные переменные.
6.2 Удаленные ссылки типа SHADOW
6.2.1 Спецификация массива с теневыми гранями
Удаленная ссылка типа SHADOW означает, что обработка удаленных данных будет происходить через “теневые” грани. Теневая грань представляет собой буфер, который является непрерывным продолжением локальной секции массива в памяти процессора (см. рис.6.1.).Рассмотрим оператор
A[i] = B[i + d2] + B[ i – d1]
где d1, d2 – целые положительные константы. Если обе ссылки на массив B являются удаленными ссылками типа SHADOW, то для массива B необходимо использовать поддирективу SHADOW [ d1 : d2], где d1 – ширина левой грани, а d2 – ширина правой грани. Для многомерных массивов необходимо специфицировать грани по каждому измерению. При спецификации теневых граней в описании массива указывается максимальная ширина по всем удаленным ссылкам типа SHADOW.
Синтаксис директивы SHADOW.
| shadow-directive | ::= | SHADOW shadow-array... |
| shadow-array | ::= | array-name shadow-edge... |
| shadow-edge | ::= | [ width ] |
| | | [ low-width : high-width ] | |
| width | ::= | int-expr |
| low-width | ::= | int-expr |
| high-width | ::= | int-expr |
Ограничение:
Размер левой теневой грани (low-width) и размер правой теневой грани (high-width) должны быть целыми константными выражениями, значения которых больше или равны 0.
Задание размера теневых граней как width эквивалентно заданию width : width.
По умолчанию, распределенный массив имеет теневые грани шириной 1 с обеих сторон каждого распределенного измерения.
6.2.2 Спецификация независимых ссылок типа SHADOW для одного цикла
Спецификация синхронного обновления теневых граней является частью директивы PARALLEL:
| shadow-renew-clause | ::= SHADOW_RENEW renewee... |
| renewee | ::= dist-array-name [ shadow-edge ]… [ CORNER ] |
Ограничения:
Выполнение синхронной спецификации заключается в обновлении теневых граней значениями удаленных переменных перед выполнением цикла.
Пример 6.1. Спецификация SHADOW-ссылок без угловых элементов
DVM(DISTRIBUTE [BLOCK]) float A[100]; DVM(ALIGN[I] WITH A[ I] ; SHADOW B[1:2]) float B[100]; . . . DVM(PARALLEL[I] ON A[I]; SHADOW_RENEW B) DO(I,1, 97,1) A[I] = (B[I-1] + B[I+1] + B[I+2]) / 3.;
При обновлении значений в теневых гранях используются максимальные размеры 1:2, заданные в директиве SHADOW.
Распределение и схема обновления теневых граней показана на рис.6.1.
Рис.6.1. Распределение массива с теневыми гранями.
На каждом процессоре распределяются два буфера, которые являются непрерывным продолжением локальной секции массива. Левая теневая грань имеет размер в 1 элемент (для B[I-1]), правая теневая грань имеет размер в 2 элемента (для B[I+1] и B[I+2]). Если перед выполнением цикла произвести обмен между процессорами по схеме на рис.6.1, то цикл может выполняться на каждом процессоре без замены ссылок на массивы ссылками на буфер.
Для многомерных распределенных массивов теневые грани могут распределяться по каждому измерению. Особая ситуация возникает, когда необходимо обновлять " угол" теневых граней. В этом случае требуется указать дополнительный параметр CORNER.
Пример 6.2. Спецификация SHADOW-ссылок с угловыми элементами
DVM(DISTRIBUTE [BLOCK][BLOCK]) float A[100][100]; DVM(ALIGN [i][j] WITH A[i][j]) float B[100][100]; . . . DVM(PARALLEL[I][J] ON A[I][J]; SHADOW_RENEW B (CORNER)) DO( I, 1, 98, 1) DO( J, 1, 98, 1) A[I][J] = (B[I][J+1] + B[I+1][J] + B[I+1][J+1]) / 3.;
Теневые грани для массива В распределяются по умолчанию размером в 1 элемент по каждому измерению. Т.к. имеется удаленная " угловая" ссылка B[I+1][J+1], то указывается параметр CORNER.

Рис. 6.2. Схема локальной секции массива с теневыми гранями.
6.2.3 Спецификация ACROSS зависимых ссылок типа SHADOW для одного цикла
Рассмотрим следующий цикл
DO(i, 1, N-2,1) DO(j, 1, N-2,1) A[i][j] =(A[i][j-1]+A[i][j+1]+A[i-1][j]+A[i+1][j])/4.;
Между витками цикла с индексами i1 и i2 ( i1<i2 ) существует зависимость по данным (информационная связь) массива A, если оба эти витка осуществляют обращение к одному элементу массива по схеме запись-чтение или чтение-запись.
Если виток i1 записывает значение, а виток i2 читает это значение, то между этими витками существует потоковая зависимость или просто зависимость i1® i2.
Если виток i1 читает “старое” значение, а виток i2 записывает “новое” значение, то между этими витками существует обратная зависимость i1¬ i2.
В обоих случаях виток i2 может выполняться только после витка i1.
Значение i2 - i1 называется диапазоном или длиной зависимости. Если для любого витка i существует зависимый виток i + d (d - константа), тогда зависимость называется регулярной или зависимостью с постоянной длиной.
Цикл с регулярными вычислениями, в котором существуют регулярные зависимости по распределенным массивам, можно распределять с помощью директивы PARALLEL, указывая спецификацию ACROSS.6.2.3.
| across-clause | ::= ACROSS dependent-array... |
| dependent-array | ::= dist-array-name dependence... |
| dependence | ::= [ flow-dep-length : anti-dep-length ] |
| flow-dep-length | ::= int-constant |
| anti-dep-length | ::= int-constant |
В спецификации ACROSS перечисляются все распределенные массивы, по которым существует регулярная зависимость по данным. Для каждого измерения массива указывается длина прямой зависимости (flow-dep-length) и длина обратной зависимости (anti-dep-length). Нулевое значение длины зависимости означает отсутствие зависимости по данным.
Пример 6.3. Спецификация цикла с регулярной зависимостью по данным.
DVM(PARALLEL [i][j] ON A[i][j]; ACROSS A[1:1][1:1]) DO(i, 1, N-2, 1) DO(j, 1, N-2, 1) A[i][j]=(A[i][j-1]+A[i][j+1]+A[i-1][j]+A[i+1][j])/4.;
По каждому измерению массива А существует прямая и обратная зависимость длиной 1.
Спецификация ACROSS реализуется через теневые грани. Длина обратной зависимости определяет ширину обновления правой грани, а длина прямой зависимости – ширину обновления левой грани. Обновление значений правых граней производится перед выполнением цикла (как для директивы SHADOW_RENEW). Обновление левых граней производится во время выполнения цикла по мере вычисления значений удаленных данных. Это позволяет организовать так называемые волновые вычисления для многомерных массивов. Фактически, ACROSS-ссылки являются подмножеством SHADOW–ссылок, между которыми существует зависимость по данным.
6.2.4 Асинхронная cпецификация независимых ссылок типа SHADOW
Обновление значений в теневых гранях, описанное в разделе 6.2.2, является неделимой (синхронной) операцией обмена для неименованной группы распределенных массивов. Эту операцию можно разделить на две операции:
На фоне ожидания значений теневых граней можно выполнять вычисления, в частности, вычисления на внутренней области локальной секции массива.
Асинхронное обновление теневых граней для именованной группы распределенных массивов описывается следующими директивами.
Создание группы.
| shadow-group-directive | ::= CREATE_SHADOW_GROUP shadow-group-name : renewee |
Запуск обновления теневых граней.
| shadow-start-directive | ::= SHADOW_START shadow-group-name |
Ожидание значений теневых граней.
| shadow-wait-directive | ::= SHADOW_WAIT shadow-group-name |
Директива SHADOW_START должна выполняться после директивы CREARE_SHADOW_GROUP. После выполнения директивы CREATE_SHADOW_GROUP директивы SHADOW_START и SHADOW_WAIT могут выполняться многократно. Новые значения в теневых гранях могут использоваться только после выполнения директивы SHADOW_WAIT.
Особым вариантом является использование директив SHADOW_START и SHADOW_WAIT в спецификации shadow-renew-clause параллельного цикла.
| shadow-renew-clause | ::= | . . . |
| | | shadow-start-directive | |
| | | shadow-wait-directive |
Если в спецификации указана директива SHADOW_START, то на каждом процессоре производится опережающее вычисление значений, пересылаемых в теневые грани других процессоров. После этого запускается обновление теневых граней и продолжается вычисление на внутренней области локальной секции массива (см. рис.6.2.).
Если в спецификации указана директива SHADOW_WAIT, то производится опережающее вычисление значений, не использующих значений из теневых граней. Остальные значения вычисляются только после завершения ожидания новых значений теневых граней.
Пример 6.4. Совмещение счета и обновления теневых граней.
DVM(DISTRIBUTE [BLOCK][BLOCK]) float C[100][100];
DVM(ALIGN[I][J] WITH C[I][J]) float A[100][100], B[100][100],
D[100][100];
DVM(SHADOW_GROUP) void *AB;
. . .
DVM(CREATE_SHADOW_GROUP AB: A B);
. . .
DVM(SHADOW_START AB);
. . .
DVM(PARALLEL[I][J] ON C[I][J]; SHADOW_WAIT AB)
DO( I, 1, 98, 1)
DO( J, 1, 98, 1)
{ C[I][J] = (A[I-1][J]+A[I+1][J]+A[I][J-1]+A[I][J+1])/4.;
D[I][J] = (B[I-1][J]+B[I+1][J]+B[I][J-1]+B[I][J+1])/4.;
}
Массивы A и B имеют теневые грани в 1 элемент по умолчанию. Ожидание завершения обновления теневых граней откладывается на возможно более позднее время, т.е. до того момента, когда без них уже нельзя продолжить вычисления.
6.3 Удаленные ссылки типа REMOTE
Удаленные ссылки типа REMOTE специфицируются директивой REMOTE_ACCESS.
| remote-access-directive | ::= REMOTE_ACCESS [ remote-group-name : ] regular-reference... |
| regular-reference | ::= dist-array-name [ regular-subscript ]… |
| regular-subscript | ::= [ int-expr ] |
| | [ do-variable-use ] | |
| | [] | |
| remote-access-clause | ::= remote-access-directive |
Директива REMOTE_ACCESS может быть отдельной директивой (область действия - следующий оператор) или дополнительной спецификацией в директиве PARALLEL (область действия – тело параллельного цикла).
Если удаленная ссылка задается как имя массива без списка индексов, то все ссылки на этот массив в параллельном цикле (операторе) являются удаленными ссылками типа REMOTE.
6.3.2 Синхронная спецификация удаленных ссылок типа REMOTE
Если в директиве REMOTE_ACCESS не указано имя группы (remote-group-name), то выполнение такой директивы происходит в синхронном режиме. В пределах нижестоящего оператора или параллельного цикла компилятор заменяет все вхождения удаленной ссылки ссылкой на буфер. Пересылка удаленных данных производится перед выполнением оператора или цикла.
Пример 6.5. Синхронная спецификация удаленных ссылок типа REMOTE.
DVM(DISTRIBUTE [][BLOCK]) float A[100][100], B[100][100]; . . . DVM(REMOTE_ACCESS A[50][50]) X = A[50][50]; . . . DVM(REMOTE_ACCESS B[100][100]) A[1][1] = B[100][100]; . . . DVM(PARALLEL[I][J] ON A[I][J]; REMOTE_ACCESS B[][N]) FOR(I, 100) FOR(J, 100) A[I][J] = B[I][J] + B[I][N];
Первые две директивы REMOTE_ACCESS специфицируют удаленные ссылки для отдельных операторов. REMOTE_ACCESS в параллельном цикле специфицирует удаленные данные (столбец матрицы) для всех процессоров, на которые распределен массив А.
6.3.3 Асинхронная спецификация удаленных ссылок типа REMOTE
Если в директиве REMOTE_ACCESS указано имя группы (remote-group-name), то выполнение директивы происходит в асинхронном режиме. Для спецификации этого режима необходимы следующие дополнительные директивы.
Описание имени группы.
| remote-group-directive | ::= REMOTE_GROUP |
Идентификатор, определенный этой директивой, может использоваться только в директивах REMOTE_ACCESS, PREFETCH и RESET.
| prefetch-directive | ::= PREFETCH group-name |
| reset-directive | ::= RESET group-name |
Рассмотрим следующую типовую последовательность асинхронной спецификации удаленных ссылок типа REMOTE.
DVM(REMOTE_GROUP) void * RS; . . . DVM(PREFETCH RS); . . . DVM(PARALLEL . . . ; REMOTE_ACCESS RS : r1) . . . DVM(PARALLEL . . . ; REMOTE_ACCESS RS : rn) . . .
При первом прохождении указанной последовательности операторов директива PREFETCH не выполняется. Директивы REMOTE_ACCESS выполняется в обычном синхронном режиме. При этом происходит накопление ссылок в переменной RS. После выполнения всей последовательности директив REMOTE_ACCESS значение переменной RS равно объединению подгрупп удаленных ссылок ri, ..., rn.
При втором и последующих прохождениях директива PREFETCH осуществляет упреждающую пересылку удаленных данных для всех ссылок, составляющих значение переменной RS. После директивы PREFETCH и до первой директивы REMOTE_ACCESS с тем же именем группы можно выполнять другие вычисления, которые перекрывают ожидание обработки удаленных ссылок. При этом директивы REMOTE_ACCESS никакой пересылки данных уже не вызывают.
Ограничения.
Если характеристики группы удаленных ссылок изменились, то необходимо присвоить неопределенное значение группе удаленных ссылок с помощью директивы RESET, после чего будет происходить новое накопление группы удаленных ссылок.
Рассмотрим следующий фрагмент многообластной задачи. Область моделирования разделена на 3 подобласти, как показано на рис.6.3.
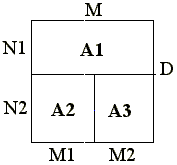
Рис.6.3. Разделение области моделирования.
Пример 6.6. Использование группы регулярных удаленных ссылок.
DVM (DISTRIBUTE [BLOCK][BLOCK])
float A1[M][N1+1], A2[M1+1][[N2+1], A3[M2+1][N2+1];
DVM (REMOTE_GROUP) void *RS;
DO(ITER,1, MIT,1)
{
. . .
/* edge exchange by split line D */
DVM (PREFETCH RS);
. . .
DVM ( PARALLEL[i] ON A1[i][N1]; REMOTE_ACCESS RS: A2[i][1])
DO(i,0, M1-1,1)
A1[i][N1] = A2[i][1];
DVM (PARALLEL[i] ON A1[i][N1]; REMOTE_ACCESS RS: A3[i-M1][1])
DO(i,M1, M-1,1)
A1[i][N1] = A3[i-M1][1];
DVM (PARALLEL[i] ON A2[i][0]; REMOTE_ACCESS RS: A1[I][N1-1])
DO(i,0, M1-1,1)
A2[i][0] = A1[i][N1-1];
DVM(PARALLEL[i] ON A3[i][0]; REMOTE_ACCESS RS: A1[I+M1][N1-1])
DO (i,0, M2-1,1) A3[i][0] = A1[i+M1][N1-1];
. . .
if (NOBLN) {
/*array redistribution to balance loading */
. . .
DVM (RESET RS);
}
. . .
} /*DO ITER*/
6.4 Удаленные ссылки типа REDUCTION
6.4.1 Синхронная спецификация удаленных ссылок типа REDUCTION
Если спецификация REDUCTION в параллельном цикле указана без имени группы, то она является синхронной спецификацией и выполняется в два этапа:
6.4.2 Асинхронная спецификация удаленных ссылок типа REDUCTION
Асинхронная спецификация позволяет:
Для асинхронной спецификации, кроме директивы REDUCTION (с именем группы), необходимы следующие дополнительные директивы.
| reduction-start-directive | ::= REDUCTION_START reduction-group-name |
| reduction-wait-directive | ::= REDUCTION_WAIT reduction-group-name |
Ограничения.
Пример 6.7. Асинхронная спецификация типа REDUCTION.
DVM(REDUCTION_GROUP) void *RG;
. . .
S = 0;
X = A[1];
Y = A[1];
MINI = 1;
DVM(PARALLEL[I] ON A[I]; REDUCTION RG: SUM(S), MAX(X), MINLOC(Y,MIMI))
FOR(I, N)
{ S = S + A[I];
X =max(X, A[I]);
if(A[I] < Y) THEN { Y = A[I]; MINI = I;}
}
DVM(REDUCTION_START RG);
DVM(PARALLEL[I] ON B[I])
FOR( I, N)
B[I] = C[I] + A[I];
DVM(REDUCTION_WAIT RG);
printf("%f %f %f %d\n", S, X, Y, MINI);
На фоне выполнения групповой редукции будут вычисляться значения элементов массива B.
Модель параллелизма DVM объединяет параллелизм по данным и параллелизм задач. Параллелизм задач реализуется независимыми вычислениями на секциях массива процессоров.
Определим множество виртуальных процессоров, на которых выполняется процедура, как текущую систему виртуальных процессоров. Для главной процедуры текущая система состоит из полного множества виртуальных процессоров.
Отдельная группа задач определяется следующими директивами:
В процедуре может быть описано несколько массивов задач. Вложенность задач не разрешается.
Массив задач описывается следующей директивой:
| task-directive | ::= TASK |
Описание задач определяет одномерный массив задач, которые затем будут отображены на секции массива процессоров.
7.2 Отображение задач на процессоры. Директива MAP
Отображение задачи на секцию массива процессоров выполняется директивой MAP
| map-directive | ::= | MAP task-name [ task-index ] |
| ONTO processors-name [ section-subscript ]… |
На одну и ту же секцию могут быть отображены несколько задач, но разные секции не могут иметь общих процессоров.
7.3 Распределение массивов по задачам
Распределение массивов по задачам осуществляется директивой REDISTRIBUTE со следующим расширением:
| dist-target | ::= . . . |
| | task-name [ task-index ] |
Массив распределяется на секцию массива процессоров, на которую уже была отображена задача.
7.4 Распределение вычислений. Директива TASK_REGION
Распределение блоков операторов по задачам описывается конструкцией TASK_REGION:
| block-task-region | ::= DVM( task-region-directive ) { on-block... } |
| task-region-directive | ::= TASK_REGION task-name |
| [ ; reduction-clause ] | |
| on-block | ::= DVM( on-directive ) operator |
| on-directive | ::= ON task-name [ task-index ] |
Область задач и каждый on-block являются последовательностями операторов с одним входом (первый оператор) и одним выходом (после последнего оператора). Для блоков операторов конструкция TASK_REGION по семантике эквивалентна конструкции параллельных секций для систем с общей памятью. Отличием является то, что блок операторов может выполняться на нескольких процессорах в модели параллелизма по данным.
Распределение витков параллельного цикла по задачам осуществляется следующей конструкцией:
| loop-task-region | ::= | DVM( task-region-directive ) { |
| parallel-task-loop | ||
| } | ||
| parallel-task-loop | ::= | DVM( parallel-task-loop-directive ) |
| do-loop | ||
| parallel-task-loop-directive | ::= | PARALLEL [ do-variable ] ON task-name [ do-variable ] |
Единицей распределенных вычислений является виток одномерного параллельного цикла. Отличием от обычного параллельного цикла является распределение витка на секцию массива процессоров. При этом секция определяется ссылкой на элемент массива задач.
Спецификация reduction-clause имеет ту же семантику, что и для параллельного цикла. Значение редукционной переменной должно быть вычислено в каждой задаче. После окончания задач в случае синхронной спецификации автоматически выполняется редукция над значениями редукционной переменной по всем задачам. В случае асинхронной спецификации запуск редукции осуществляется директивой REDUCTION_START.
7.5 Локализация данных в задачах
Задачей является on-block или виток цикла. Задачи одной группы имеют следующие ограничения по данным
7.6 Фрагмент статической многообластной задачи
Ниже приведен фрагмент программы, описывающей реализацию 3-х областной задачи (рис. 6.2.) в модели параллелизма по данным.
DVM(PROCESSORS) void *P[NUMBER_OF_PROCESSORS()];
/* arrays A1,А2,А3 - the values on the previous iteration */
/* arrays В1,В2,В3 - the values on the current iteration */
DVM(DISTRIBUTE) float (*A1)[N1+1],(*A2)[N2+1],(*A3)N2+1];
DVM(ALIGN) float (*B1)[N1+1], (*B2)[N2+1], (*B3)[N2+1];
/* description of task array */
DVM(TASK) void *MB[3];
DVM (REMOTE_GROUP) void *RS;
. . .
/* distribution of tasks on processor arrangement */
/* sections and distribution of arrays on tasks */
/* (each section contain third of all the processors) */
NP = NUMBER_OF_PROCESSORS()/3;
DVM(MAP MB[1] ONTO P(0: NP-1));
A1=malloc(M*(N1+1)*sizeof(float));
DVM(REDISTRIBUTE A1[][BLOCK] ONTO MB[1]);
B1=malloc(M*(N1+1)*sizeof(float));
DVM(REALIGN B1[i][j] WITH A1[i][j]);
DVM(MAP MB[2] ONTO P( NP : 2*NP-1));
A2=malloc((M1+1)*(N2+1)*sizeof(float));
DVM(REDISTRIBUTE A2[][BLOCK] ONTO MB[2]);
B2=malloc((M1+1)*(N2+1)*sizeof(float));
DVM(REALIGN B2[i][j] WITH A2[i][j]);
DVM(MAP MB[3] ONTO P(2*NP : 3*NP-1));
A3=malloc((M1+1)*(N2+1)*sizeof(float));
DVM(REDISTRIBUTE A3[][BLOCK] ONTO MB[3]);
B3=malloc((M1+1)*(N2+1)*sizeof(float));
DVM(REALIGN B3[i][j] WITH A3[i][j]);
. . .
FOR(IT,MAXIT)
{. . .
DVM(PREFETCH RS);
/* exchanging edges of adjacent blocks */
. . .
/* distribution of statement blocks on tasks */
DVM(TASK_REGION MB)
{
DVM(ON MB[1]) JACOBY(A1, B1, M, N1+1);
DVM(ON MB[2]) JACOBY(A2, B2, M1+1, N2+1);
DVM(ON MB[3]) JACOBY(A3, B3, M2+1, N2+1);
} /* TASK_REGION */
} /* FOR */
7.7 Фрагмент динамической многообластной задачи
Рассмотрим фрагмент программы, которая динамически настраивается на количество областей и размеры каждой области.
#define NA 20 /* NA - maximal number of blocks */
DVM(PROCESSORS) void *R[NUMBER_OF_PROCESSORS()];
int SIZE[2][NA]; /* sizes of dynamic arrays */
/* arrays of pointers for А и В */
DVM(* DISTRIBUTE) float *PA[NA];
DVM(* ALIGN) float *PB[NA];
DVM(TASK) void *PT[NA];
. . .
NP = NUMBER_OF_PROCESSORS( );
/* distribution of arrays on tasks */
/* dynamic allocation of the arrays */
/* and execution of postponed directives */
/* DISTRIBUTE and ALIGN */
FOR(i,NA)
{
DVM(MAP PT[I] ONTO R[ i%(NP/2) : i%(NP/2)+1] );
PA[i] = malloc(SIZE[0][i]*SIZE[1][i]*sizeof(float));
DVM(REDISTRIBUTE (PA[i])[][BLOCK] ONTO PT[I]);
PB[i] = malloc(SIZE[0][i]*SIZE[1][i]*sizeof(float));
DVM(REALIGN (PB[i])[I][J] WITH (PA[i])[I][J])
} /*FOR i */
. . .
/* distribution of computations on tasks */
DVM(TASK_REGION PT) {
DVM(PARALLEL[i] ON PT[i])
FOR(i,NA)
JACOBY(PA[i], PB[i], SIZE[0][i], SIZE[1][i]);
}
} /* TASK_REGION */
Массивы (области) циклически распределяются на секции из 2-х процессоров. Если NA > NP/2, то на некоторые секции будет распределено несколько подзадач. Витки циклов, распределенные на одну секцию, будут выполняться последовательно в модели параллелизма по данным.
Вызов процедуры из параллельного цикла.
Процедура, вызываемая из параллельного цикла, не должна иметь побочных эффектов и содержать обменов между процессорами (прозрачная процедура). Как следствие этого, прозрачная процедура не содержит операторов ввода-вывода и DVM-директив;
Вызов процедуры вне параллельного цикла.
Если фактическим аргументом является явно распределенный массив (DISTRIBUTE или ALIGN), то он должен передаваться без изменения формы. Это означает, что фактический аргумент является ссылкой на начало массива, а соответствующий формальный аргумент имеет конфигурацию, полностью совпадающую с конфигурацией фактического аргумента.
Формальные параметры.
Если фактическим параметром функции может быть распределенный массив, то формальный параметр должен быть описан следующим образом:
Локальные массивы.
Локальные массивы могут распределяться в процедуре директивами DISTRIBUTE и ALIGN. Локальный массив может быть выровнен на формальный аргумент. Директива DISTRIBUTE распределяет локальный массив на ту подсистему процессоров, на которой была вызвана процедура (текущая подсистема). Если в директиве DISTRIBUTE указана секция массива процессоров, то количество этих процессоров должно быть равно количеству процессоров текущей подсистемы.
Пример 9.1. Распределение локальных массивов и формальных аргументов.
void dist(
/* explicit distribution of formal argument */
DVM(*DISTRIBUTE[][BLOCK]) float *A /* N*N */,
/* aligned formal argument */
DVM(*ALIGN [i][j] WITH A[i][j]) float *B /* N*N */,
/* inherited distribution of the formal argument */
DVM(*) float *C /* N*N */,
int N)
{
DVM(PROCESSORS) void *PA[NUMBER_OF_PROCECCORS()];
/* local array aligned with formal argument */
DVM(ALIGN[I][J] WITH C[I][J]) float *X;
/* distributed local array */
DVM(DISTRIBUTE [][BLOCK] ONTO PA) float *Y;
}
Замечание. Размеры массивов фактических параметров неизвестны, поэтому здесь должна использоваться техника работы с динамическими многомерными массивами, описанная в разделе 4.2.3.
В C-DVM, разрешены следующие операции ввода/вывода для размноженных данных:
fopen, fclose, feof, fprintf, printf, fscanf, fputc, putc, fputs, puts, fgetc, getc, fgets, gets, fflush, fseek, ftell, ferror, clearerr, perror, as well as fread, fwrite.
Эти операторы выполняются на выделенном процессоре (процессоре ввода/вывода). Выводимые значения берутся на этом процессоре, а вводимые – вводятся на нем и рассылаются на остальные процессоры.
Для распределенных данных обеспечивается только бесформатный ввод/вывод массива целиком функциями fread/fwrite.
Функции ввода/вывода не следует использовать в параллельных циклах и в блоках TASK_REGION, т.к. выводимые данные окажутся в файле (на печати) в непредсказуемом порядке.
10 Ограничения на использование языка СИ
C-DVM предназначен для распараллеливания вычислительных программ, написанных в "фортрано-подобном" стиле. При этом на использование средств языка СИ накладываются некоторые ограничения. В первую очередь эти органичения касаются использования указателей на распределенные массивы и их элементы. C-DVM не запрещает использовать указатели, но некоторые операции с ними могут стать некорректными после конвертирования программы. Например:
Второе ограничение касается типов данных: элементы распределенных массивов могут быть только скалярных типов int, long, float и double.
Далее, некоторые описания для распараллеливания требуют выполнения определенных действий. Это например:
Такого рода неявные действия для глобальных объектов выполняются в начале функции main сразу после инициализации системы поддержки. Поэтому в момент генерации main все такие объекты должны быть известны, т.е. не могут находиться в отдельно транслируемом файле или следовать за описанием функции main. Для объектов, локальных в функции или блоке, эти действия выполняются перед первым оператором блока. Кроме того заметим, что неявные действия выполняются в порядке описаний, и это накладывает определенные семантические ограничения на порядок описаний: база ALIGN должна быть описана до выравниваемого массива и т.п.
И наконец, использование препроцессора, выходящее за пределы файлов заголовков, требует осторожности по нескольким причинам. Во-первых, C-DVM компилятор работает до препроцессора. Поэтому, например, пара определений
#define begin {
#define end }
может сделать программу совершенно непонятной для компилятора. По этой же причине DVM-директивы в файле заголовков остаются неизвестными компилятору. Следовательно, распределенные данные должны быть описаны явно в каждом файле. Во-вторых, для работы с многомерными массивами (см. 4.2) предлагается использовать препроцессор для временного переопределения размеров массивов как констант или для определения макрокоманд, моделирующих многомерный массив на одномерном. В конвертированной программе соответствующие препроцессорные директивы должны быть удалены. Это реализовано тем, что все директивы препроцессора в исходном порядке помещаются в начало выходного файла. (Заметим, что для каждой вспомогательной директивы #define требуется директива #undef, отменяющая ее.)
11 Отличия версии 2.0 от версии 1.0
C-DVM 1.0 является подмножеством C-DVM 2.0. Добавлены следующие новые возможности:
11.1 Копирование секций массивов
Язык C-DVM предоставляет средства для копирования распределенных массивов (секций распределенных массивов), которые позволяют обеспечить совмещение обмена данных с вычислениями.
Прямоугольная секция массива задается триплетами (<начало>:<конец>:<шаг>) по каждой размерности массива. Для присваивания секции должны иметь одинаковые ранги, т.е. одинаковое число невырожденных размерностей (массивы при этом могут иметь разные ранги), одинаковое число элементов в соответствующих невырожденных размерностях секции источника и получателя.
Для того, чтобы C-DVM программа могла компилироваться и выполняться как обычная последовательная программа, копирование массивов (секций) записывается как обычный многомерный цикл. Тело цикла должно состоять из единственного оператора присваивания. Заголовки цикла должны быть записаны макрокомандами DO(v,first,last,step) или FOR(v,times). Все переменные цикла должны использоваться в индексных выражениях правой и левой части оператора присваивания, причем в одном и том же порядке. Каждое индексное выражение может содержать только одну переменную цикла и должно зависеть от нее линейно.
Для асинхронного копирования нужно:
Пример 11.1. Асинхронное копирование.
DVM(DISTRIBUTE [BLOCK][]) float
A[N][N];
DVM(ALIGN [i][j] WITH [j][i]) float B[N][N];
. . .
DVM(COPY_FLAG) void * flag;
. . .
DVM(COPY_START &flag)
FOR(i,N)
FOR(j,N)
B[i][j]=A[i][j];
. . .
DVM(COPY_WAIT &flag);
Если совмещение обменов с вычислениями не требуется, то можно несколько упростить программу, использу директиву синхронного копирования COPY.
Пример 11.2. Синхронное копирование.
DVM(COPY)
FOR(i,N)
FOR(j,N)
B[i][j]=A[i][j];
Синтаксис.
| copy-flag-directive | ::= COPY_FLAG |
| copy-start-directive | ::= COPY_START flag_addr |
| copy-wait-directive | ::= COPY_WAIT flag_addr |
| copy-directive | ::= COPY |
| C-DVM - оглавление | Часть 1 (1-4) | Часть 2 (5-11) | Часть 3 (Приложения) |