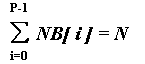
| C-DVM - оглавление | Часть 1 (1-4) | Часть 2 (5-11) | Часть 3 (Приложения) |
| создан: апрель 2001 | - последнее обновление 07.10.02 - |
Язык C-DVM предназначен для разработки мобильных и эффективных параллельных программ вычислительного характера. Он представляет собой расширение языка Си в соответствии с моделью DVM, разработанной в ИПМ им М.В.Келдыша РАН [1].
Вычислительные программы для последовательных ЭВМ традиционно создавались на языках Фортран 77 и Cи. Для многопроцессорных ЭВМ с распределенной памятью и сетей ЭВМ такие программы в настоящее время, как правило, создаются на языках Фортран 77 и Cи, расширенных библиотеками передачи сообщений (PVM, MPI). Разработка таких параллельных программ требует от прикладного программиста гораздо больших усилий, чем разработка последовательных программ, поскольку ему требуется не только распределить данные и вычисления между разными процессорами, но и организовать взаимодействие процессоров посредством обмена сообщениями. Фактически, параллельная программа представляет собой систему взаимодействующих программ, каждая из которых выполняется на своем процессоре. Программы на разных процессорах могут быть совершенно различными, могут различаться лишь незначительно, а могут являться одной программой, поведение которой зависит от номера процессора. Но даже в этом последнем случае, программист обычно вынужден разрабатывать и сопровождать два различных варианта своей программы -- последовательный и параллельный.
При использовании языка C-DVM программист имеет только один вариант программы и для последовательного и для параллельного выполнения. Эта программа, помимо описания алгоритма обычными средствами языка Си, содержит правила параллельного выполнения этого алгоритма. Эти правила оформляются синтаксически таким образом, что они являются “невидимыми” для стандартных компиляторов с языка Си для последовательных ЭВМ и не препятствуют выполнению и отладке DVM-программы на рабочих станциях как обычной последовательной программы.
Таким образом, язык C-DVM представляет собой стандартный язык Си, дополненный средствами спецификации параллельного выполнения программы:
Для создания программ на языке C-DVM служит специальная система автоматизации разработки параллельных программ – DVM-система.
DVM-система предоставляет единый комплекс средств для разработки параллельных программ научно-технических расчетов на языках Си и Фортран 77.
Модель параллелизма DVM. Модель параллелизма DVM базируется на модели параллелизма по данным. Аббревиатура DVM отражает два названия модели: распределенная виртуальная память (Distributed Virtual Memory) и распределенная виртуальная машина (Distributed Virtual Mashine). Эти два названия указывают на адаптацию модели DVM как для систем с общей памятью, так и для систем с распределенной памятью. Высокоуровневая модель DVM позволяет не только снизить трудоемкость разработки параллельных программ, но и определяет единую формализованную базу для систем поддержки выполнения, отладки, оценки и прогноза производительности.
Языки и компиляторы. В отличие от стандарта HPF в системе DVM не ставилась задача полной автоматизации распараллеливания вычислений и синхронизации работы с общими данными. С помощью высокоуровневых спецификаций программист полностью управляет эффективностью выполнения параллельной программы.
Единая модель параллелизма встроена в языки Си и Фортран 77 на базе конструкций, которые “невидимы” для стандартных компиляторов, что позволяет иметь один экземпляр программы для последовательного и параллельного выполнения. Компиляторы с языков C-DVM и Fortran DVM переводят DVM-программу в программу на соответствующем последовательном языке (Си или Фортран 77) с вызовами функций системы поддержки параллельного выполнения (Lib-DVM). Поэтому единственным требованием к параллельной системе является наличие компиляторов с языков Си и Фортран 77.
Технология выполнения и отладки. Единая модель параллелизма позволяет иметь для двух языков единую систему поддержки выполнения и, как следствие, единую систему отладки, анализа и прогноза производительности. Выполнение и отладка DVM-программ может осуществляться в следующих режимах:
При псевдо-параллельном и параллельном выполнении возможны следующие режимы отладки:
2.1 Модель программирования и модель параллелизма
Язык C-DVM является расширением ANSI-C специальными аннотациями (DVM-директивами). Директивы записываются как параметры макроса
DVM(<directive>)
который в последовательной программе “расширяется” в пустую строку.
DVM-директивы могут быть условно разбиты на три класса:
Модель параллелизма DVM базируется на специальной форме параллелизма по данным: одна программа – множество потоков данных (SPMD). В этой модели одна и та же программа выполняется на каждом процессоре, но каждый процессор выполняет свое подмножество операторов в соответствии с распределением данных.
В модели DVM пользователь вначале определяет многомерный массив виртуальных процессоров, на секции которого будут распределяться данные и вычисления. При этом секция может варьироваться от полного массива процессоров до отдельного процессора.
На следующем этапе определяются массивы, которые должны быть распределены между процессорами (распределенные данные). Эти массивы специфицируются директивами отображения данных (раздел 4). Остальные переменные (распределяемые по умолчанию) отображаются по одному экземпляру на каждый процессор (размноженные данные). Размноженная переменная должна иметь одно и то же значение на каждом процессоре за исключением переменных в параллельном цикле (разделы 5.1.3, 5.1.4 и 7.5).
Распределение данных определяет множество локальных или собственных переменных для каждого процессора. Множество собственных переменных определяет правило собственных вычислений: процессор присваивает значения только собственным переменным.
Модель DVM определяет два уровня параллелизма:
Параллелизм по данным реализуется распределением витков тесно-гнездового цикла между процессорами массива (или секции массива) процессоров (раздел 5). При этом каждый такого цикла полностью выполняется на одном процессоре. Операторы вне параллельного цикла выполняются по правилу собственных вычислений (раздел 5.2).
Параллелизм задач реализуется распределением данных и вычислений на (разные) секции массива процессоров (раздел 7).
При вычислении значения собственной переменной процессору могут потребоваться как значения собственных переменных, так и значения несобственных (удаленных) переменных. Все удаленные переменные должны быть указаны в директивах доступа к удаленным данным (раздел 6).
Синтаксис DVM-директив описывается расширенной БНФ. Используются следующие обозначения:
| ::= | есть по определению, |
| x | y | альтернативы, |
| [ x ] | необязательный элемент/конструкция, |
| [ x ]… | повторение 0 или более раз, |
| x... | повторение 1 или более раз; эквивалентно x [ x ]… |
Синтаксис директив.
| directive | ::= DVM ( DVM-directive [ ; DVM-directive ]… ) | |
| DVM-directive | ::= specification-directive | executable-directive |
|
| specification-directive | ::= processors-directive | align-directive | distribute-directive | template-directive | shadow-directive | shadow-group-directive | reduction-group-directive | remote-group-directive | task-directive |
|
| executable-directive | ::=
realign-directive | redistribute-directive | create-template-directive | parallel-directive | remote-access-directive | create-shadow-group-directive | shadow-start-directive | shadow-wait-directive | reduction-start-directive | reduction-wait-directive | prefetch-directive | reset-directive | map-directive | task-region-directive | on-directive |
|
Ограничения:
3 Массивы виртуальных процессоров. Директива PROCESSORS
Директива PROCESSORS определяет один или несколько массивов виртуальных процессоров на текущем множестве физических процессоров.
Синтаксис:
| processors-directive | ::= PROCESSORS |
Можно определить несколько массивов виртуальных процессоров разной формы при условии, что количество процессоров в каждом массиве будет равно числу физических процессоров. Если два массива виртуальных процессоров имеют одинаковую форму, то соответствующие элементы этих массивов ссылаются на один и тот же процессор. Для определения количества физических процессоров, предоставленных программе (или подзадаче), может использоваться встроенная функция NUMBER_OF_PROCESSORS ( ).
Замечание1. Массив процессоров описывается в Си как массив типа void*.
Замечание2. Чтобы программа компилировалась как последовательная в ней должно присутствовать определение:
#define NUMBER_OF_PROCESSORS() 1
Пример 3.1. Описание массивов виртуальных процессоров.
DVM(PROCESSORS) void *P[N]; DVM(PROCESSORS) void *Q[NUMBER_OF_PROCESSORS()], *R[2][NUMBER_OF_PROCESSORS()/2];
В этом примере значение N должно быть равно значению функции NUMBER_OF_PROCESSORS ( ) и оба должны быть четными.
C-DVM поддерживает распределение блоками (равными и неравными) и распределение через выравнивание.
4.1 Директивы DISTRIBUTE и REDISTRIBUTE
Синтаксис:
| distribute-directive | ::= | DISTRIBUTE [ dist-directive-stuff ] |
| redistribute-directive | ::= | REDISTRIBUTE distributee dist-directive-stuff [ NEW ] |
| distributee | ::= | array-name |
| dist-directive-stuff | ::= | dist-format... [ dist-onto-clause ] |
| dist-format | ::= | | | |
[BLOCK] [GENBLOCK ( block-array-name )] [WGTBLOCK ( block-array-name,nblock )] [] |
| dist-onto-clause | ::= | ONTO dist-target |
| dist-target | ::= | processors-name [ section-subscript ]… |
| section-subscript | ::= | [ subscript [ : subscript ] ] |
Ограничения:
Рассмотрим форматы распределения для одного измерения массива (одномерный массив A[N]) и для одного измерения массива процессоров (одномерный массив R[P]). Многомерные распределения рассматриваются в разделе 4.1.4.
Измерение массива распределяется последовательно блоками по [N/P] элементов. Если размерность не делится нацело, то образуется один частично заполненный и, возможно, несколько пустых блоков.
Пример 4.1. Распределение по формату BLOCK.
| A | B | C | ||||
| R[0] | 0 | 0 | 0 | |||
| 1 | 1 | 1 | ||||
| DVM(PROCESSORS) void * R[4]; | 2 | 2 | ||||
| DVM(DISTRIBUTE [BLOCK] ONTO R) | 3 | |||||
| float A [12], B[13], C[5]; | ||||||
| R[1] | 3 | 4 | 2 | |||
| 4 | 5 | 3 | ||||
| 5 | 6 | |||||
| 7 | ||||||
| R[2] | 6 | 8 | 4 | |||
| 7 | 9 | |||||
| 8 | 10 | |||||
| 11 | ||||||
| R[3] | 9 | 12 | ||||
| 10 | ||||||
| 11 | ||||||
Распределение блоками разных размеров позволяет влиять на балансировку загрузки процессоров для алгоритмов, которые выполняют разное количество вычислений на различных участках области данных.
Пусть NB[P] - массив целых чисел. Следующая директива
DVM(DISTRIBUTE [ GENBLOCK(NB) ] ONTO R) float A[N];
разделяет массив A на P блоков. Блок i размера NB[i] распределяется на процессор R[i]. При этом должно выполняться равенство
Пример 4.2. Распределение неравными блоками.
| A | ||
| R[0] | 0 | |
| DVM(PROCESSORS) void * R[ 4]; | 1 | |
| int BS[4]={2,4,4,2}; | ||
| DVM(DISTRIBUTE [ GENBLOCK(BS)] ONTO R) | R[1] | 2 |
| float A[12]; | 3 | |
| 4 | ||
| 5 | ||
| R[2] | 6 | |
| 7 | ||
| 8 | ||
| 9 | ||
| R[3] | 10 | |
| 11 | ||
Формат WGTBLOCK определяет распределение блоками по их относительным “весам”.
Пусть задан формат WGTBLOCK(WB, NBL).
WB(i) определяет вес i-го блока для 0 <= i <= NBL-1. Блоки распределяются на P процессоров с балансировкой сумм весов блоков на каждом процессоре. При этом должно выполняться условие P <= NBL.
Определим вес процессора как сумму весов всех блоков, распределенных на него. Измерение массива распределяется пропорционально весам процессоров.
Формат BLOCK является частным случаем формата WGTBLOCK(WB,P), где WB(i) = 1 для 0 <= i <= P-1 и NBL = P.
Формат GENBLOCK с некоторой точностью является частным случаем формата WGTBLOCK.
Пример 4.2 можно переписать с использованием формата WGTBLOCK следующим образом.
Пример 4.3. Распределение блоками по весам.
| DVM(PROCESSORS) void * R[ 4]; |
| int WS[12]={2.,2.,1.,1.,1.,1.,1.,1.,1.,1.,2.,2.}; |
| DVM(DISTRIBUTE [ WGTBLOCK(WS,12)] ONTO R) |
| float A[12]; |
В примере 4.3 P = 4 и распределение идентично примеру 4.2.
В отличие от распределения неравными блоками, распределение по формату WGTBLOCK можно выполнить для любого числа процессоров в диапазоне 1 <= P <= NBL. Для данного примера размер массива процессоров R может меняться от 1 до 12.
Формат ‘[ ]’ означает, что измерение не распределяется, т.е. присутствует на каждом процессоре целиком.
4.1.5 Многомерные распределения
При многомерных распределениях формат распределения указывается для каждого измерения. Между измерениями распределяемого массива и массива процессоров устанавливается следующее соответствие.
Пусть массив процессоров имеет n измерений. Пронумеруем измерения массива без формата ‘[ ]’ слева направо d1, ..., dk.. Тогда измерение di будет распределяться на i-ое измерение массива процессоров. При этом должно выполняться условие k<=n.
Пример 4.3. Одномерное распределение.
| DVM(PROCESSORS) void R1[2]; |
Блоки A |
Процессоры |
||
| DVM(DISTRIBUTE [BLOCK][] ONTO R1) | 1 | 0 | 1 | |
| float A[100][100]; | 2 | 1 | 2 | |
Пример 4.4. Двумерное распределение.
| DVM(PROCESSORS) void *R2 [2][2]; | Блоки A | Процессоры | |||
|
0 |
1 |
||||
| DVM(DISTRIBUTE [BLOCK][BLOCK] | 1 | 2 | 0 | 1 | 2 |
| ONTO R2) float A[100][100]; | 3 | 4 | 1 | 3 | 4 |
4.2 Многомерные динамические массивы
4.2.1 Динамические массивы в языке Си
DVM-система имеет расширенные возможности работы с динамическими массивами. Она позволяет создавать многомерные массивы, размеры которых по всем измерениям определяются во время выполнения. (Язык Cи позволяет не определять статически только старшую размерность). Многомерные массивы разных размеров (а иногда и размерностей) можно передавать как параметры. В языке C-DVM предлагаются два способа работы с многомерными динамическими массивами. Первый основан на использовании многомерных массивов Cи. Второй состоит в моделировании многомерных массивов одномерными.
4.2.2 Использование многомерных массивов Си
Предлагается следующая дисциплина описания, создания, уничтожения и использования элементов многомерных динамических массивов:
| elem_type | - тип элемента массива, |
| arrid | - идентификатор массива, |
| dimi | - размер по i-му измерению. |
Компилятор преобразует эти конструкции в корректные описания и обращения к системе поддержки. Но чтобы программа могла транслироваться как последовательная обычным Cи компилятором, все размерности dimi (кроме первой) должны быть константами. Предлагается в точке определения массива временно переопределить их как константы (#define dimi const …#undef dimi). Компилятор удаляет эти переопределения, точнее, перемещает их в начало файла. Естественно, что фактические (“вычисленные” в переменных) размерности при последовательном выполнении должны совпадать с выбранными константными значениями. (см. пример Красно-черного SOR в Приложении 1).
Пример определения массива.
DVM(DISTRIBUTE [BLOCK][BLOCK]) float (*C)[N];
4.2.3 Моделирование многомерных массивов одномерными
Для работы с многомерными динамическими массивами в Cи используется и другой метод. Создается (одномерная) область памяти нужного размера, а для доступа к элементам “многомерного массива” используется макрос arrid(ind1,...,indn), который вычисляет позицию элемента с указанными индексами в отведенной массиву области памяти. В этом случае обращения к массивам выглядят так же, как в Фортране.
Такой способ работы тоже поддерживается компилятором C-DVM.
Пример описания массива (одномерный для последовательной программы, но двумерный для параллельного выполнения) и ссылки на его элементы:
int Cdim2; /* The second dimension of array C */ DVM(DISTRIBUTE [BLOCK][]) float *C; #define C(x,y) C[(x)*Cdim2+(y)] . . . C(i,j) = (C(i,j-1)+C(i,j+1))/2;
4.3 Распределение выравниванием
Выравнивание массива А на распределенный массив В ставит в соответствие каждому элементу массива А элемент или секцию массива В. Распределение элементов массива В определяет распределение элементов массива А. Если на некоторый процессор распределен элемент В, то на этот же процессор будут распределены элементы массива А, поставленные в соответствие с ним выравниванием.
Метод распределения через выравнивание выполняет следующие две функции.
4.3.1 Директивы ALIGN и REALIGN
Выравнивание массива описывается следующими директивами:
| align-directive | ::= ALIGN [ align-directive-stuff ] |
| realign-directive | ::= REALIGN
alignee align-directive-stuff [ NEW ] |
| align-directive-stuff | ::= align-source... align-with-clause |
| alignee | ::= array-name |
| align-source | ::= [] |
| | [ align-dummy ] | |
| align-dummy | ::= scalar-int-variable |
| align-with-clause | ::= WITH align-spec |
| align-spec | ::= align-target [ align-subscript ]… |
| align-target | ::= array-name |
| | template-name | |
| align-subscript | ::= [ int-expr ] |
| | [ align-subscript-use ] | |
| | [] | |
| align-subscript-use | ::= [ primary-expr * ] align-dummy [ add-op primary-expr ] |
| primary-expr | ::= int-constant |
| | int-variable | |
| | ( int-expr ) | |
| add-op | ::= + |
| | - |
Ограничения:
Пусть задано выравнивание двух массивов с помощью директивы
DVM(ALIGN [d1]…[dn] WITH B[ard1]…[ardm]) float A[100]…[100];
где
di -
спецификация i-го
измерения выравниваемого массива А,
ardj
- спецификация j-го
измерения базового массива В,
Если di задано целочисленной переменной I, то обязательно должно существовать одно и только одно измерение массива В, специфицированное линейной функцией ardj = a*I + b. Следовательно, количество измерений массива А, специфицированных идентификаторами (align-dummy) должно быть равно количеству измерений массива В, специфицированных линейной функцией.
Пусть i-ое
измерение массива А имеет размер Ai,
а j-ое измерение
массива В, специфицированное линейной
функцией a*I + b, имеет
размер Bj. Т.к.
параметр I определен
над множеством значений 0…Ai-1,
то должны выполняться следующие условия:
b >= 0
, а*(Ai
–1)+ b < Bj
Если di пусто, то i-ое измерение массива А будет локальным на каждом процессоре при любом распределении массива В (аналог локального измерения в директиве DISTRIBUTE ).
Если ardi пусто, то массив А будет размножен по j-му измерению массива В (аналог частичного размножения по массиву процессоров).
Если ardi = int-expr, то массив А выравнивается на секцию массива В.
Пример 4.7. Выравнивание массивов
DVM(DISTRIBUTE [BLOCK][BLOCK]) float B[10][10]; DVM(DISTRIBUTE [BLOCK]) float D[20]; /* aligning the vector A with the first line of B) */ DVM(ALIGN [i] WITH B[0][i] ) float A[10]; /* replication of the vector aligning it with each line */ DVM(ALIGN [i] WITH B[][i]) float F[10]; /* collaps: each column corresponds to the vector element */ DVM(ALIGN [][i] WITH D[i]) float C[20][20]; /* alignment using stretching */ DVM(ALIGN [i] WITH D[2*i]) float E[10]; /* alignment using rotation and stretching */ DVM(ALIGN [i][j] WITH C[2*j][2*i] ) float H[10,10];
Пусть заданы выравнивания f1 и f2, причем f2 - выравнивает массив В по массиву С, а f1 - выравнивает массив А массиву В. По определению массивы А и В считаются выровненными на массив С. Массив В выровнен непосредственно функцией f2, а массив А выровнен опосредовано составной функцией f1(f2). Поэтому применение директивы REALIGN к массиву В не вызовет перераспределения массива А.
В общем случае множество спецификаций ALIGN образует лес деревьев. При этом корень каждого дерева должен быть распределен директивами DISTRIBUTE или REDISTRIBUTE. При выполнении директивы REDISTRIBUTE перераспределяется все дерево выравниваний.
4.3.2 Директивы TEMPLATE и CREATE_TEMPLATE
Если значения линейной функции a*I + b выходят за пределы измерения базового массива, то необходимо определить фиктивный массив - шаблон выравнивания следующей директивой:
| template-directive | ::= TEMPLATE [ size ]… |
Затем необходимо произвести выравнивание обоих массивов на этот шаблон. Шаблон распределяется с помощью директив DISTRIBUTE и REDISTRIBUTE. Элементы шаблона не требуют памяти, они указывают процессор, на который должны быть распределены элементы выровненных массивов.
Рассмотрим следующий пример.
Пример 4.8. Выравнивание по шаблону.
DVM(DISTRIBUTE [BLOCK]; TEMPLATE[102]) void * TABC; DVM(ALIGN B[i] WITH TABC[i]) float B[100]; DVM(ALIGN A[i] WITH TABC[i+1]) float A[100]; DVM(ALIGN C[i] WITH TABC[i+2]) float C[100]; . . . DO(i,1, 98,1) A[i] = C[i-1] + B[i+1];
Если размеры шаблона (и массивов) не известны статически, то следует использовать следующую выполняемую директиву:
| create-template-directive | ::= CREATE_TEMPLATE template_name size... |
Пример 4.9. Выравнивание по динамическому шаблону.
DVM(DISTRIBUTE [BLOCK]; TEMPLATE ) void *TABC; DVM(ALIGN B[i] WITH TABC[i]) float *B; DVM(ALIGN A[i] WITH TABC[i+1]) float *A; DVM(ALIGN C[i] WITH TABC[i+2]) float *C; int N; . . . N= ... /* вычисляем размер */...; DVM(CREATE_TEMPLATE TABC[N]); A=malloc(N*sizeof(float)); B=malloc(N*sizeof(float)); C=malloc(N*sizeof(float)); . . .DO(i,1, N-2,1) A[i] = C[i-1] + B[i+1];
Если для данных не указана директива DISTRIBUTE или ALIGN, то эти данные распределяются на каждом процессоре (полное размножение). Такое же распределение можно определить директивой DISTRIBUTE, указав для каждого измерения формат [ ]. Но в этом случае доступ к данным будет менее эффективным.
| C-DVM - оглавление | Часть 1 (1-4) | Часть 2 (5-11) | Часть 3 (Приложения) |