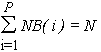| Fortran-DVM - оглавление | Часть
1 (1-4) |
Часть 2 (5-6) | Часть 3 (7-12) | Часть 4 (Приложения) |
| создан: апрель, 2001 | - последнее обновление 06.10.02 - |
1.1. Модели параллельного программирования
В настоящее время в области научно-технических расчетов превалируют три модели параллельного программирования: модель передачи сообщений (МПС), модель с общей памятью (МОП) и модель параллелизма по данным (МПД).
Модель передачи сообщений. В модели передачи сообщений каждый процесс имеет собственное локальное адресное пространство. Обработка общих данных и синхронизация осуществляется посредством передачи сообщений. Обобщение и стандартизация различных библиотек передачи сообщений привели к разработке стандарта MPI [1].
Модель с общей памятью. В модели с общей памятью процессы разделяют общее адресное пространство. Так как нет ограничений на использование общих данных, то программист должен явно специфицировать общие данные и упорядочивать доступ к ним с помощью средств синхронизации. В языках высокого уровня логически независимые нити (потоки) вычислений определяются на уровне функциональных задач или витков цикла. Обобщение и стандартизация моделей с общей памятью привели к созданию стандарта OpenMP [2].
Модель параллелизма по данным. В модели параллелизма по данным отсутствует понятие процесса и, как следствие, явная передача сообщений или явная синхронизация. В этой модели данные последовательной программы распределяются по узлам (процессорам) вычислительной системы. Последовательная программа преобразуется компилятором либо в модель передачи сообщений, либо в модель с общей памятью (рис.1.1). При этом вычисления распределяются по правилу собственных вычислений: каждый процессор выполняет только вычисления собственных данных, т.е. данных, распределенных на этот процессор.
По сравнению с двумя предыдущими моделями МПД имеет явные преимущества. Эта модель освобождает программиста от рутинной и трудоемкой работы по распределению глобальных массивов на локальные массивы процессов, по управлению передачей сообщений и синхронизации доступа к общим данным. Однако область применения этой модели является предметом исследований. Результаты этих исследований показывают, что эффективность многих алгоритмов научно-технических расчетов в модели МПД сравнима с эффективностью реализации в моделях МПС и МОП.
Первой попыткой стандартизации МПД для научно-технических расчетов явилась разработка HPF1 [3]. Стандартизация моделей МПС и МОП проводилась на базе обобщения большого опыта реализации и практического применения этих моделей. Стандарт HPF1 разрабатывался на базе теоретических исследований и 2-3 экспериментальных реализаций. Кроме этого, стандарт базировался на полной автоматизации распараллеливания вычислений и синхронизации работы с общими данными. Первые реализации HPF1 показали неэффективность стандарта для современных методов вычислений (в частности, для нерегулярных вычислений). В следующей версии стандарта HPF2 [4] сделан шаг в сторону “ручного” управления эффективностью параллельного выполнения. В частности, определены средства распределения вычислений и спецификации общих редукционных переменных.
Рис.1.1. Три модели параллельного программирования
1.2. DVM–подход к разработке параллельных программ
DVM-система предоставляет единый комплекс средств для разработки параллельных программ научно-технических расчетов на языках Си и Фортран 77.
Модель параллелизма DVM. Модель параллелизма DVM базируется на модели параллелизма по данным. Аббревиатура DVM отражает два названия модели: распределенная виртуальная память (Distributed Virtual Memory) и распределенная виртуальная машина (Distributed Virtual Mashine). Эти два названия указывают на адаптацию модели DVM как для систем с общей памятью, так и для систем с распределенной памятью. Высокоуровневая модель DVM позволяет не только снизить трудоемкость разработки параллельных программ, но и определяет единую формализованную базу для систем поддержки выполнения, отладки, оценки и прогноза производительности.
Языки и компиляторы. В отличие от стандарта HPF в системе DVM не ставилась задача полной автоматизации распараллеливания вычислений и синхронизации работы с общими данными. С помощью высокоуровневых спецификаций программист полностью управляет эффективностью выполнения параллельной программы. С другой стороны, при проектировании и развитии языка Fortran DVM отслеживалась совместимость с подмножеством стандартов HPF1 и HPF2.
Единая модель параллелизма встроена в языки Си и Фортран 77 на базе конструкций, которые “невидимы” для стандартных компиляторов, что позволяет иметь один экземпляр программы для последовательного и параллельного выполнения. Компиляторы с языков C-DVM и Fortran DVM переводят DVM-программу в программу на соответствующем языке (Си или Фортран 77) с вызовами функций системы поддержки параллельного выполнения. Поэтому единственным требованием к параллельной системе является наличие компиляторов с языков Си и Фортран 77.
Технология выполнения и отладки. Единая модель параллелизма позволяет иметь для двух языков единую систему поддержки выполнения и, как следствие, единую систему отладки, анализа и прогноза производительности. Выполнение и отладка DVM-программ может осуществляться в следующих режимах:
При псевдо-параллельном и параллельном выполнении возможны следующие режимы отладки:
2.1. Модель программирования и модель параллелизма
Язык Fortran DVM (FDVM) представляет собой язык Фортран 77 [5], расширенный спецификациями параллелизма. Эти спецификации оформлены в виде специальных комментариев, которые называются директивами. Директивы FDVM можно условно разделить на три подмножества:
Модель параллелизма FDVM базируется на специальной форме параллелизма по данным: одна программа – множество потоков данных (ОПМД). В этой модели одна и та же программа выполняется на каждом процессоре, но каждый процессор выполняет свое подмножество операторов в соответствии с распределением данных.
В модели FDVM пользователь вначале определяет многомерный массив виртуальных процессоров, на секции которого будут распределяться данные и вычисления. При этом секция может варьироваться от полного массива процессоров до отдельного процессора.
На следующем этапе определяются массивы, которые должны быть распределены между процессорами (распределенные данные). Эти массивы специфицируются директивами отображения данных (раздел 4). Остальные переменные (распределяемые по умолчанию) отображаются по одному экземпляру на каждый процессор (размноженные данные). Размноженная переменная должна иметь одно и то же значение на каждом процессоре за исключением переменных в параллельных конструкциях (см. раздел 5.1.3, 5.1.4 и 7.5).
Модель FDVM определяет два уровня параллелизма:
Параллелизм по данным реализуется распределением витков тесно-гнездового цикла между процессорами (раздел 5). При этом каждый виток такого параллельного цикла полностью выполняется на одном процессоре. Операторы вне параллельного цикла выполняются по правилу собственных вычислений (раздел 5.2).
Параллелизм задач реализуется распределением данных и независимых вычислений на секции массива процессоров (раздел 7).
При вычислении значения собственной переменной процессору могут потребоваться как значения собственных переменных, так и значения несобственных (удаленных) переменных. Все удаленные переменные должны быть указаны в директивах доступа к удаленным данным (раздел 6).
Синтаксис директив FDVM описывается следующей БНФ формой:
| is or [ ] [ ]… x-list |
по
определению альтернатива необязательная конструкция повторение конструкции 0 или более раз x [ , x ]… |
Синтаксис директивы.
| directive-line | is CDVM$ dvm-directive |
| or *DVM$ dvm-directive | |
| dvm-directive | is specification-directive |
| or executable-directive | |
| or heap-directive | |
| or asyncid-directive | |
| specification-directive | is processors-directive |
| or align-directive | |
| or distribute-directive | |
| or template-directive | |
| or pointer-directive | |
| or shadow-directive | |
| or dynamic-directive | |
| or inherit-directive | |
| or remote-group-directive | |
| or reduction-group-directive | |
| or task-directive | |
| executable-directive | is realign-directive |
| or redistribute-directive | |
| or parallel-directive | |
| or remote-access-directive | |
| or shadow-group-directive | |
| or shadow-start-directive | |
| or shadow-wait-directive | |
| or reduction-start-directive | |
| or reduction-wait-directive | |
| or new-value-directive | |
| or prefetch-directive | |
| or reset-directive | |
| or parallel-task-loop-directive | |
| or map-directive | |
| or task-region-directive | |
| or end-task-region-directive | |
| or on-directive | |
| or end-on-directive |
| or f90-directive | |
| or asynchronous-directive | |
| or end-asynchronous-directive | |
| or asyncwait-directive |
Ограничения:
Никакой оператор не может находиться среди строк продолжения директивы. Строка directive-line не может находиться внутри продолженного оператора. Ниже приводится пример директивы с продолжением. Отметим, что позиция 6 должна быть пробелом за исключением случая, когда она используется для обозначения продолжения.
CDVM$ ALIGN SPACE1( I, J, K )
CDVM$* WITH SPACE(J
, K, I )
3. Массивы виртуальных процессоров. Директива PROCESSORS
Директива PROCESSORS определяет один или несколько массивов виртуальных процессоров.
Синтаксис.
| processors-directive | is PROCESSORS processors-decl-list |
| processors-decl | is processors-name ( explicit-shape-spec-list ) |
| explicit-shape-spec | is [ lower-bound : ] upper-bound |
| lower-bound | is int-expr |
| upper-bound | is int-expr |
Встроенная функция NUMBER_OF_PROCESSORS ( ) может использоваться для определения количества физических процессоров, на которых выполняется вся программа.
Разрешается использовать несколько массивов виртуальных процессоров разной формы при следующем условии: количество процессоров в каждом массиве должно быть равно значению встроенной функции NUMBER_OF_PROCESSORS ( ). Если два массива виртуальных процессоров имеют одинаковую форму, то соответствующие элементы этих массивов ссылаются на один виртуальный процессор.
Пример 3.1. Описание массивов виртуальных процессоров.
CDVM$ PROCESSORS P( N )
CDVM$ PROCESSORS Q( NUMBER_OF_PROCESSORS( ) ),
CDVM$* R(2, NUMBER_OF_PROCESSORS( )/2)
Значение N должно быть равно значению функции NUMBER_OF_PROCESSORS ( ).
Массивы процессоров являются локальными объектами процедуры. Массивы данных с атрибутами COMMON и SAVE могут быть отображены на локальные массивы виртуальных процессоров при следующем условии: при каждом вызове процедуры локальный массив процессоров имеет одно и то же определение.
FDVM поддерживает распределение блоками (равными и неравными), наследуемое распределение, распределение динамических массивов и распределение через выравнивание.
4.1. Директивы DISTRIBUTE и REDISTRIBUTE
Синтаксис.
| distribute-directive | is dist-action distributee dist-directive-stuff |
| or dist-action [ dist-directive-stuff ] :: distributee-list | |
| dist-action | is DISTRIBUTE |
| or REDISTRIBUTE | |
| dist-directive-stuff | is dist-format-list [ dist-onto-clause ] |
| distributee | is array-name |
| dist-format | is BLOCK |
| or GEN_BLOCK ( block-size-array ) | |
| or WGT_BLOCK ( block-weight-array , nblock) |
| or * | |
| dist-onto-clause | is ONTO dist-target |
| dist-target | is
processors-name [(processors-section-subscript-list )] |
| processors-section-subscript | is [ subscript ] : [ subscript ] |
| subscript | is int-expr |
| nblock | is int-expr |
| block-size-array | is array-name |
| block-weight-array | is array-name |
Ограничения:
Спецификация ONTO указывает массив или секцию массива виртуальных процессоров. Если спецификация ONTO не указана, то распределение осуществляется по базовому массиву виртуальных процессоров, который является параметром запуска программы на выполнение. Когда директива REDISTRIBUTE без спецификации ONTO выполняется в ON-блоке, то распределение осуществляется на секцию массива процессоров этого ON-блока (см. радел 7).
Несколько одинаково распределяемых массивов (A1, A2,…) можно распределить одной директивой вида
CDVM$ DISTRIBUTE dist-directive-stuff :: A1, A2, …
При этом массивы должны иметь одинаковое число измерений, но необязательно одинаковые размеры измерений.
Рассмотрим форматы распределения для одного измерения массива (одномерный массив A(N) ) и для одного измерения массива процессоров (одномерный массив R(P) ). Многомерные распределения рассматриваются в разделе 4.1.5.
На каждом процессоре распределяется блок размером [ (N-1)/P] +1 элементов. При некоторых соотношениях N и P несколько последних процессоров могут не содержать значений элементов массива.
Пример 4.1. Распределение по формату BLOCK
| A | B | C | |||||
| R(1) | 1 | 1 | 1 | ||||
| 2 | 2 | 2 | |||||
| CDVM$ PROCESSORS R( 4 ) | 3 | 3 | 3 | ||||
| 4 | |||||||
| REAL A (12), B(13), C(11) | R(2) | 4 | 5 | 4 | |||
| 5 | 6 | 5 | |||||
| 6 | 7 | 6 | |||||
| CDVM$ DISTRIBUTE A (BLOCK) ONTO R | 8 | ||||||
| R(3) | 7 | 9 | 7 | ||||
| CDVM$ DISTRIBUTE (BLOCK) ONTO R :: B | 8 | 10 | 8 | ||||
| 9 | 11 | 9 | |||||
| 12 | |||||||
| CDVM$ DISTRIBUTE C (BLOCK) | |||||||
| R(4) | 10 | 13 | 10 | ||||
| 11 | 11 | ||||||
| 12 | |||||||
Распределение блоками разных размеров позволяет влиять на балансировку загрузки процессоров для алгоритмов, которые выполняют разное количество вычислений на различных участках области данных.
Пусть NB( 1:P ) - массив целых чисел. Следующая директива
CDVM$ DISTRIBUTE A( GEN_BLOCK(NB)) ONTO R
разделяет массив A на P блоков. Блок i размера NB( i ) распределяется на процессор R( i ). При этом
Пример 4.2. Распределение неравными блоками.
| A | |||
| R(1) | 1 | ||
| CDVM$ PROCESSORS R( 4 ) | 2 | ||
| R(2) | 3 | ||
| INTEGER BS(4) | 5 | ||
| 6 | |||
| REAL A(12) | |||
| R(3) | 7 | ||
| 8 | |||
| CDVM$ DISTRIBUTE A ( GEN_BLOCK( BS ) ) ONTO R | 9 | ||
| 10 | |||
| DATA BS / 2, 4, 4, 2 / | R(4) | 11 | |
| 12 | |||
Формат WGT_BLOCK определяет распределение блоками по их относительным “весам”.
Пусть задан формат WGT_BLOCK(WB, NBL).
Для 1<= i <= NBL, WB(i) определяет вес i-ого блока. Блоки распределяются на P процессоров с балансировкой сумм весов блоков на каждом процессоре. При этом должно выполняться условие
P <= NBL
Определим вес процессора как сумму весов всех блоков, распределенных на него. Измерение массива распределяется пропорционально весам процессоров.
Формат BLOCK является частным случаем формата WGT_BLOCK(WB,P), где WB(i) = 1 для 1<= i <= P и NBL = P.
Формат GEN_BLOCK с некоторой точностью является частным случаем формата WGT_BLOCK.
Пример 4.2 можно переписать с использованием формата WGT_BLOCK следующим образом.
Пример 4.3. Распределение блоками по весам.
CDVM$ PROCESSORS R( 4 )
DOUBLE
PRECISION WB(12)
REAL
A(12)
CDVM$ DISTRIBUTE A ( WGT_BLOCK( WB, 12 ) ) ONTO R
DATA
WB / 2., 2.,1., 1., 1., 1., 1., 1., 1., 1., 2., 2. /
В примере 4.3 P = 4 и распределение идентично примеру 4.2.
В отличие от распределения неравными блоками, распределение по формату WGT_BLOCK можно выполнить для любого числа процессоров в диапазоне 1 <= P <= NBL. Для данного примера размер массива процессоров R может изменяться от 1 до 12.
Формат * означает, что измерение будет полностью локализовано на каждом процессоре (нераспределенное или локальное измерение).
4.1.5. Многомерные распределения
При многомерных распределениях формат распределения указывается для каждого измерения. Между измерениями распределяемого массива и массива процессоров устанавливается следующее соответствие.
Пусть массив процессоров имеет n измерений. Пронумеруем измерения массива без формата * слева направо d1, ..., dk.. Тогда измерение di будет распределяться на i-ое измерение массива процессоров. При этом должно выполняться условие k=n.
Пример 4.4. Одномерное распределение.
| CDVM$ PROCESSORS R1( 2 ) | Блоки A | Процессоры | ||||
| REAL A(100,100) | ||||||
| CDVM$ DISTRIBUTE A (BLOCK, *) ONTO R1 | 1 | A( 1: 50,1:100) | 1 | 1 | ||
| 2 | A(51:100,1:100) | 2 | 2 | |||
Пример 4.5. Двумерное распределение.
| CDVM$ PROCESSORS R2( 2, 2 ) | Блоки A | Процессоры | ||||
| REAL A(100,100) | 1 | 2 | ||||
| CDVM$ DISTRIBUTE A (BLOCK,BLOCK) | 1 | 2 | 1 | 1 | 2 | |
| CDVM$* ONTO R2 | 3 | 4 | 2 | 3 | 4 | |
4.2. Распределение динамических массивов
4.2.1. Динамические массивы в программе на языке Фортран 77
Отсутствие средств работы с динамическими массивами в языке Фортран 77 заставляет пользователей моделировать динамическую память с помощью так называемых рабочих массивов. Динамическая память описывается как одномерный массив большого размера. Динамические массивы разной формы определяются как непрерывные сегменты в этом рабочем массиве.
Пример 4.6. Использование рабочего массива.
REAL
HEAP(100000)
READ (6 , *) N, M
C в
программе требуются динамические массивы
размера N*N
и M* M
CALL SUB1(HEAP(1), N,
HEAP(1+N*N), M)
END
SUBROUTINE SUB1(A, N, B,
M)
DIMENSION A(N , N), B(M ,
M)
. . .
END
Анализ существующих программ показал отсутствие определенной дисциплины работы с моделируемыми динамическими массивами. В частности, отсутствует явная фиксация размещения массива в памяти. Обращение к динамическому массиву осуществляется ссылкой на рабочий массив. Это делает невозможным для компилятора определить форму массива.
4.2.2. Динамические массивы в модели FDVM. Директива POINTER
Предлагаемая модель является подмножеством модели динамических массивов Фортран 90 и позволяет без изменений выполнять эту модель в трех средах программирования
Для динамических массивов, распределяемых по умолчанию, FDVM разрешает использовать любые способы моделирования динамической памяти. Для динамических массивов, распределяемых директивами DISTRIBUTE и ALIGN, FDVM определяет следующую дисциплину размещения и использования динамических массивов.
* Все явно распределяемые динамические массивы размещаются в пуле динамической памяти с именем HEAP
REAL HEAP (MAXM)
где MAXM - количество слов динамической памяти.
* Тип данных и количество измерений динамического массива фиксируется следующей директивой FDVM
| pointer-directive | is type , POINTER ( dimension-list ) :: pointer-name-list |
| dimension | is : |
| pointer-name | is scalar-int-variable-name |
| or int-array-name |
type определяет тип данных динамического массива. Переменные, специфицированные директивой POINTER, имеют следующие ограничения.
* Размеры каждого измерения и размещение динамического массива в HEAP фиксируется следующим оператором
pointer = ALLOCATE ( sdim ,... )
где
| pointer | - ссылка на целочисленную переменную (скаляр или элемент массива) с атрибутом POINTER |
| sdim | - целочисленный одномерный массив размера ndim. ndim - количество измерений многомерного массива, размещаемого в динамической памяти HEAP. Значение sdim( i ) определяет размер i-ого измерения. Размер выделяемого сегмента равен sdim( 1 )* sdim( 2 )* ....* sdim( ndim ). |
Целочисленная функция ALLOCATE выдает номер начального элемента выделяемого сегмента динамической памяти HEAP. Функция ALLOCATE программируется пользователем, поэтому она может иметь дополнительные параметры помимо обязательного параметра sdim.
* В процедуре, где производится размещение динамического массива, разрешается только следующий тип ссылки на динамический массив
HEAP( pointer )
При этом такая ссылка может быть только фактическим аргументом вызова функции или подпрограммы.
Пусть в программе используется несколько пулов динамической памяти с идентификаторами ID1 , …, IDn. Нет необходимости переписывать программу с одним пулом динамической памяти HEAP. Достаточно указать следующую спецификацию
CDVM$ HEAP ID1 , …, IDn
Но каждый пул IDi должен удовлетворять вышеуказанным требованиям пула HEAP.
Пул может содержать только массивы, распределяемые директивами DISTRIBUTE и ALIGN.
4.2.3. Директива DISTRIBUTE и REDISTRIBUTE для динамических массивов
Для распределения динамических массивов используются директивы DISTRIBUTE и REDISTRIBUTE, синтаксис которых расширен следующим образом:
| distributee | is . . . |
| or pointer-name |
Если в качестве distributee указан скаляр или массив с атрибутом POINTER , то распределение откладывается до выполнения функции ALLOCATE, которая присваивает значение данному указателю. Вместо функции ALLOCATE выполняется создание массива и его распределение по форматам директивы DISTRIBUTE.
Директива REDISTRIBUTE для динамического массива может выполняться только после выполнения функции ALLOCATE, которая присваивает значение соответствующей переменной POINTER.
Если указатель динамического массива является элементом массива указателей, то распределить динамический массив можно только директивой REDISTRIBUTE. Т.к. директива REDISTRIBUTE допускает лишь ссылку на имя указателя, то элемент массива указателей необходимо предварительно переслать в скалярную переменную-указатель. Распределить массив с указателем PT(I) можно с помощью следующей последовательности операторов:
P1
= PT( I )
CDVM$ REDISTRIBUTE P1( BLOCK, BLOCK )
Программу, приведенную в примере 4.6, необходимо трансформировать в следующую FDVM программу.
Пример 4.7. Распределение динамических массивов FDVM.
REAL
HEAP(100000)
INTEGER
ALLOCATE
CDVM$ REAL, POINTER ( : , : ) :: PA, PB
INTEGER
PA, PB
C дескрипторы
динамических массивов
INTEGER
DESCA(2), DESCB(2)
CDVM$ DISTRIBUTE (BLOCK , BLOCK) :: PA, PB
C
в
программе требуются массивы размера N*N и M*M
READ
(6 , *) N, M
C конфигурация
первого массива
DESCA(1)
= N
DESCA(2)
= N
C размещение
и распределение первого массива
PA
= ALLOCATE (DESCA,1)
C конфигурация
второго массива
DESCB(1)
= M
DESCB(2)
= M
C размещение
и распределение второго массива
PB
= ALLOCATE ( DESCB, N*N+1 )
CALL
SUB1(HEAP(PA), N, HEAP(PB), M)
END
SUBROUTINE
SUB1(A, N, B, M)
DIMENSION
A(N , N), B(M , M)
CDVM$ DISTRIBUTE *(BLOCK , BLOCK) :: A, B
.
. .
END
FUNCTION
ALLOCATE(DESC, P)
INTEGER
DESC(2), P
ALLOCATE
= P
END
Другие примеры распределения динамических массивов см. в разделе 7.7.
4.3. Распределение через выравнивание
Выравнивание массива А на распределенный массив В ставит в соответствие каждому элементу массива А элемент или секцию массива В. При распределении массива В одновременно будет распределяться массив А. Если на данный процессор распределен элемент В, то на этот же процессор будет распределен элемент массива А, поставленный в соответствие выравниванием.
Метод распределения через выравнивание выполняет следующие две функции.
4.3.1. Директивы ALIGN и REALIGN
Выравнивание массива описывается следующими директивами:
| align-directive | is align-action alignee align-directive-stuff |
| or align-action [ align-directive-stuff ] :: alignee-list | |
| align-action | is ALIGN |
| or REALIGN | |
| align-directive-stuff | is ( align-source-list ) align-with-clause |
| alignee | is array-name |
| align-source | is * |
| or align-dummy | |
| align-dummy | is scalar-int-variable |
| align-with-clause | is WITH align-spec |
| align-spec | is align-target ( align-subscript-list ) |
| align-target | is array-name |
| or template-name | |
| align-subscript | is int-expr |
| or align-dummy-use | |
| or * | |
| align-dummy-use | is [ primary-expr * ] align-dummy [ add-op primary-expr ] |
| primary-expr | is int-constant |
| or int-variable | |
| or ( int-expr ) | |
| add-op | is + |
| or - | |
Ограничения:
Пусть задано выравнивание двух массивов с помощью директивы
CDVM$ ALIGN A(d1,…,dn) WITH B(ard1,…,ardm)
где di
-
спецификация i-го
измерения выравниваемого массива А,
ardj
- спецификация j-го
измерения базового массива В,
Если di задано целочисленной переменной I , то обязательно должно существовать одно и только одно измерение массива В , специфицированное линейной функцией ardj = a*I + b. Следовательно, количество измерений массива А, специфицированных идентификаторами (align-dummy) должно быть равно количеству измерений массива В, специфицированных линейной функцией.
Пусть i-ое измерение массива А имеет границы LAi : HAi , а j-ое измерение массива В, специфицированное линейной функцией a*I + b , имеет границы LBj : HBj. Т.к. параметр I определен над множеством значений LAi : HAi , то должны выполняться следующие условия
a*LAi + b >= LBj , а* HAi + b =< HBj
Если di = * , то i-ое измерение массива А будет локальным на каждом процессоре при любом распределении массива В (аналог локального измерения в директиве DISTRIBUTE ).
Если ardi = * , то массив А будет размножен по j-му измерению массива В (аналог частичного размножения по массиву процессоров).
Если ardi = int - expr, то массив А выравнивается на секцию массива В.
Пример 4.8. Выравнивание массивов
REAL
A(10), B(10,10), C(22,22), D(20), E(20), F(10), G(20), H(10,10)
CDVM$ DISTRIBUTE B ( BLOCK , BLOCK )
CDVM$ DISTRIBUTE D ( BLOCK )
C выравнивание
на секцию массива (вектор на первую строку
матрицы А)
CDVM$ ALIGN A( I ) WITH B( 1, I )
С размножение
вектора - выравнивание на каждую строку
CDVM$ ALIGN F( I ) WITH B( *, I
)
С сжатие
матрицы - столбец матрицы соответствует
элементу вектора
CDVM$ ALIGN C( *, I ) WITH D( I )
С выравнивание
вектора на вектор с раздвижкой
CDVM$ ALIGN E( I ) WITH D( 2*I
)
С выравнивание
вектора на вектор с реверсом
CDVM$ ALIGN G( I ) WITH D( -I + 21)
С выравнивание
матрицы на матрицу с поворотом и раздвижкой
CDVM$ ALIGN H( I, J ) WITH C( 2*J, 2*I )
Несколько массивов (A1, A2,…) можно выровнять одинаковым образом на один и тот же массив B одной директивой вида
CDVM$ ALIGN (d1,…,dn) WITH B(ard1,…,ardm) :: A1, A2, …
При этом массивы A1, A2… должны иметь одинаковое число измерений (n), но необязательно одинаковые размеры измерений.
Пусть задана цепочка выравниваний A f1 B f2 C, где f2 - выравнивание массива В на массив С , а f1 - выравнивание массива А на массив В. По определению массивы А и В считаются выровненными на массив С. Массив В выровнен непосредственно функцией f2, а массив А выровнен опосредовано составной функцией f1(f2). Поэтому применение директивы REALIGN к массиву В не вызовет перераспределения массива А.
В общем случае множество спецификаций ALIGN образует лес деревьев. При этом корень каждого дерева должен быть распределен директивами DISTRIBUTE или REDISTRIBUTE. При выполнении директивы REDISTRIBUTE перераспределяется все дерево выравниваний.
Если значения линейной функции a*I + b выходят за пределы измерения базового массива, то необходимо определить фиктивный массив - шаблон выравнивания следующей директивой:
| template-directive | is TEMPLATE template-decl-list |
| template-decl | is template-name [ ( explicit-shape-spec-list ) ] |
Затем необходимо произвести выравнивание обоих массивов на этот шаблон. Шаблон распределяется с помощью директив DISTRIBUTE и REDISTRIBUTE. Элементы шаблона не требуют памяти, они указывают процессор, на который должны быть распределены элементы выровненных массивов.
Рассмотрим следующий пример.
Пример 4.8. Выравнивание по шаблону.
REAL
A(100), B(100), C(100)
CDVM$ TEMPLATE TABC (102)
CDVM$ ALIGN B( I ) WITH TABC( I )
CDVM$ ALIGN A( I ) WITH TABC( I + 1 )
CDVM$ ALIGN C( I ) WITH TABC( I + 2 )
CDVM$ DISTRIBUTE TABC ( BLOCK )
.
. .
DO
10 I = 2, 98
A(I)
= C(I-1) + B(I+1)
10 CONTINUE
Для того, чтобы не было обмена между процессорами необходимо разместить элементы A(I), C(I-1) и B(I+1) на одном процессоре. Выравнивание массивов С и В на массив А невозможно, т.к. функции выравнивания I-1 и I+1 выводят за пределы индексов измерения А. Поэтому описывается шаблон TABC. На один элемент шаблона TABC выравниваются элементы массивов A, В и С, которые должны быть размещены на одном процессоре.
4.3.3. Выравнивание динамических массивов
Для спецификации выравнивания динамических массивов синтаксис директив ALIGN и REALIGN расширен следующим образом.
| alignee | is
. . . or pointer-name |
| align-target | is
. . . or pointer-name |
Если в директиве ALIGN в качестве выравниваемого массива (alignee) указана переменная с атрибутом POINTER, то выполнение директивы откладывается до выполнения функции ALLOCATE, которая определяет значение этой переменной. Директива REALIGN может выполняться только после выполнения функции ALLOCATE.
Пример 4.10. Выравнивание динамических массивов.
REAL
HEAP(100000)
CDVM$ REAL, POINTER ( :, : ) :: PX, PY
INTEGER
PX, PY, DESC(2)
CDVM$ ALIGN PY( I, J ) WITH PX( I, J )
CDVM$ DISTRIBUTE PX ( BLOCK, BLOCK )
.
. .
PX
= ALLOCATE(DESC, ...)
PY
= ALLOCATE(DESC, ...)
.
. .
CDVM$ REDISTRIBUTE PX ( BLOCK, * )
Пусть задана цепочка выравниваний директивами ALIGN
P1 f1 P2 f2 . . . fN-1 PN
где fi
- функция выравнивания,
Pi
- указатель на динамический массив.
Тогда размещение динамических массивов (выполнение функции ALLOCATE) должно происходить в обратном порядке, т.е.
PN = ALLOCATE(...)
. . .
P2 = ALLOCATE(...)
P1 = ALLOCATE(...)
Если указатель
динамического массива является элементом
массива указателей, то выравнивание
динамического массива можно выполнить
только директивой REALIGN. Т.к.
директива REALIGN
допускает лишь ссылку на имя указателя, то
элемент массива указателей необходимо
предварительно переслать в скалярную
переменную-указатель. Выравнивание массива
с указателем PT(I)
на массив с указателем PT(J)
можно выполнить с помощью следующей
последовательности операторов:
P1
= PT( I )
P2
= PT( J )
CDVM$ REALIGN P1( I, J ) WITH P2( I+1, J )
4.4. Директивы DYNAMIC и NEW_VALUE
Массивы, перераспределяемые директивами REDISTRIBUTE и REALIGN, необходимо специфицировать в директиве DYNAMIC.
| dynamic-directive | is DYNAMIC alignee-or-distributee-list |
| alignee-or-distributee | is alignee |
| or distributee |
Если после выполнения директив REDISTRIBUTE и REALIGN перераспределяемые массивы получают новые значения, то перед этими директивами следует указать дополнительную (оптимизирующую) директиву NEW_VALUE.
| new-value-directive | is NEW_VALUE |
Эта директива отменяет пересылку значений распределенного массива.
Если массив указан в спецификации DYNAMIC и для него нет спецификации DISTRIBUTE или ALIGN , то его распределение откладывается до первого оператора REDISTRIBUTE или REALIGN. Такая необходимость возникает в двух случаях:
4.5. Распределение по умолчанию
Если для данных не указана директива DISTRIBUTE или ALIGN , то эти данные распределяются на каждом процессоре (полное размножение). Такое же распределение можно определить директивой DISTRIBUTE , указав для каждого измерения формат *. Но в этом случае доступ к данным будет менее эффективным.
| Fortran-DVM - оглавление | Часть 1(1-4) | Часть 2 (5-6) | Часть 3 (7-12) | Часть 4 (Приложения) |